- 软件大小:34.92MB
- 软件语言:简体中文
- 软件类型:国产软件
- 软件类别:图像其它
- 更新时间:2018-05-23
- 软件授权:免费版
- 官方网站://www.9553.com
- 运行环境:XP/Win7/Win8/Win10
- 标签:汉王pdf ocr PDF文件处理扫描软件
34.92MB/简体中文/7.5
FreePic2Pdf(图片转PDF工具) 绿色中文版 v5.11
4.38MB/简体中文/5
Adobe InDesign CC 简体中文绿色精简版 Ansifa作品
132.09MB/简体中文/4.3
Adobe InDesign CS6 简体中文绿色精简版 Ansifa作品
86.54MB/简体中文/4.6
12.92MB/简体中文/7.3
汉王pdf ocr是一款OCR文字识别软件,这款软件可以帮助进行文字的扫面工作,可以将纸质内容转换为电脑的pdf文件内容,还可以进行pdf文件与word进行转换。该软件正确率高,识别速度快。目前小编为大家推荐该软件 8.0破解版本,并附上安装教程,还有软件使用过程中遇到的问题和处理。如果你需要这款软件,那就来下载使用吧!
1、双击汉王 PDF OCR安装包,打开安装向导,单击【下一步】
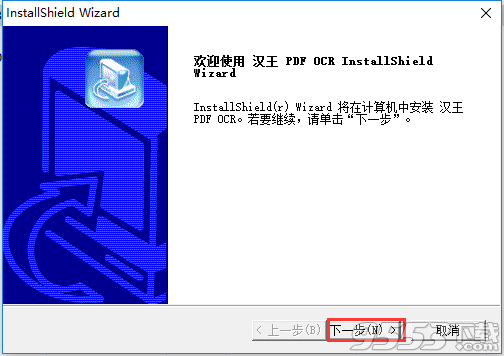
2、同意许可证协议,单击【是】
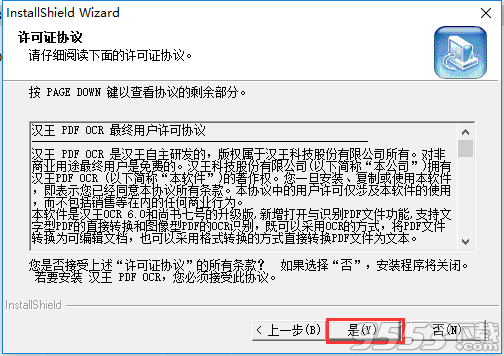
3、单击【浏览】选择软件安装位置,单击【下一步】
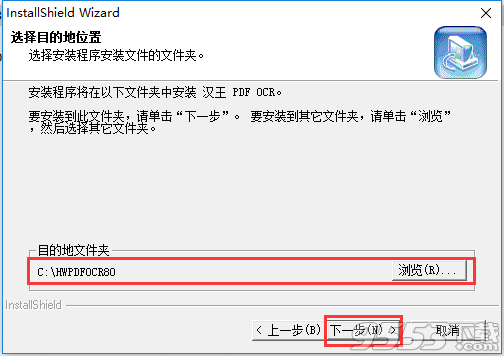
4、耐心等待一下软件安装
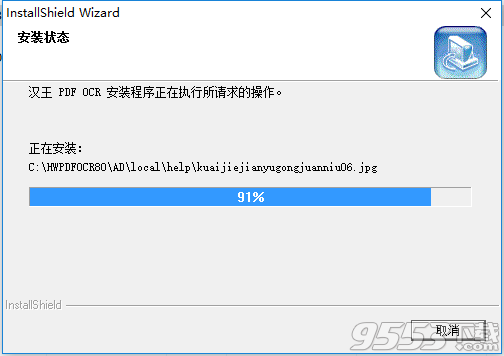
5、安装完成,单击【完成】就可以使用软件了
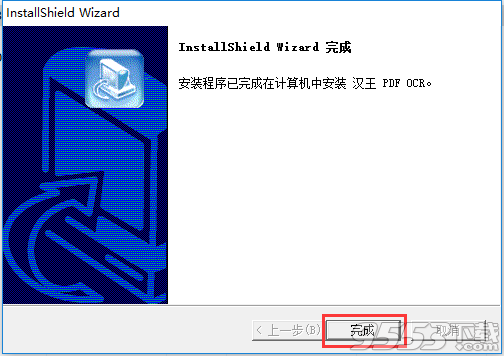
汉王pdf OCR8.1.03中文版(图片上文字转换成word文字的软件)安装:
下载软件并解压后,上图中为解压缩后的文件,双击Setup.exe,按照默认设置进行安装.
安装后默认在桌面形成快捷方式:

双击桌面快捷方式图标,运行。
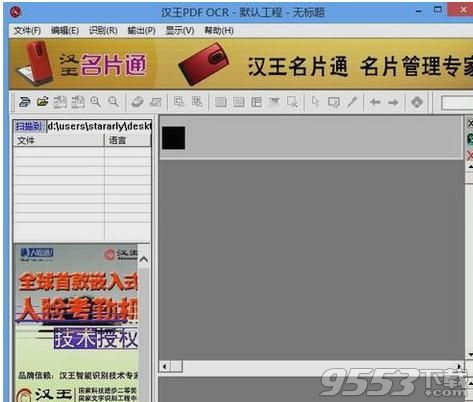
点击"打开图像"按钮图标,导入准备识别的图片:
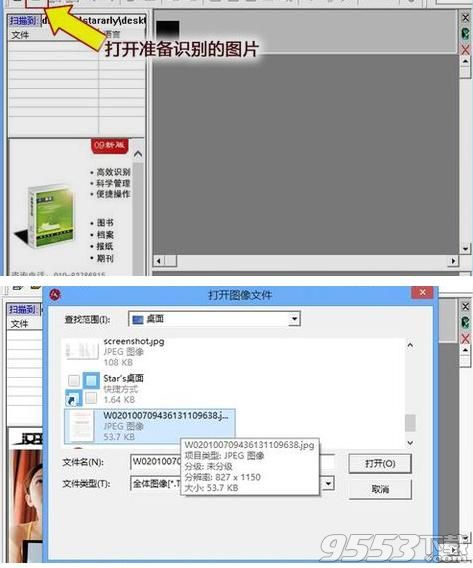
导入后,字左侧列表会显示图片,可以导入多张图片,选中后,右侧下半部分窗体会显示本章图片的内容。然后直接用鼠标拖拽,选中准备识别的部分:

选中准备识别的部分后,点击"开始识别"按钮,准备识别。
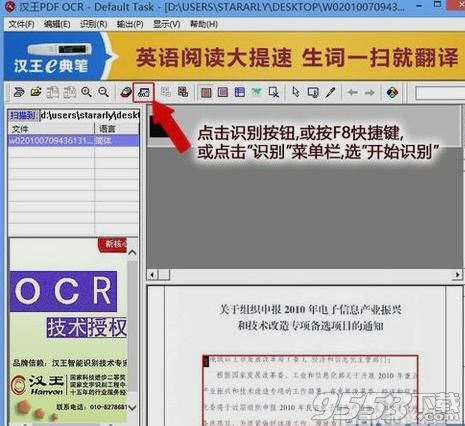
选择“开始识别”后的状态如下:
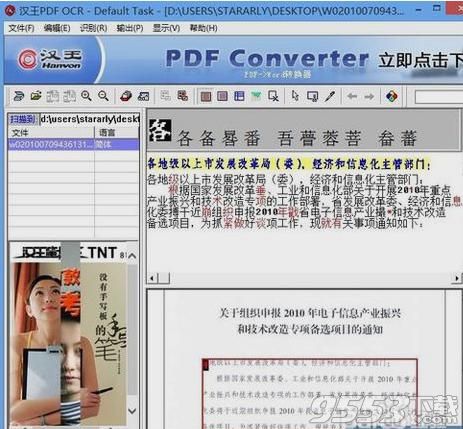
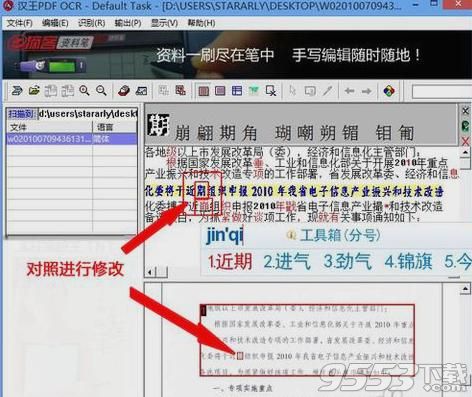
点击识别后,内容已经识别出来了,但根据图片材料的质量,识别出来的内容可能会有些错误,可以参考对照栏的内容将识别后的内容进行微调,修改:
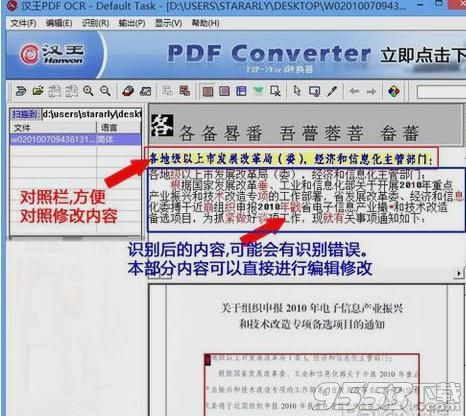
对照进行修改:
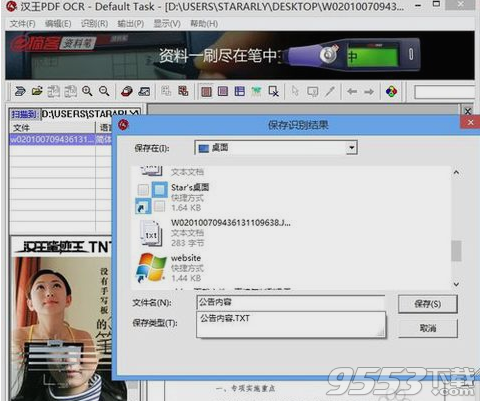
修改好后,将文本内容导出:
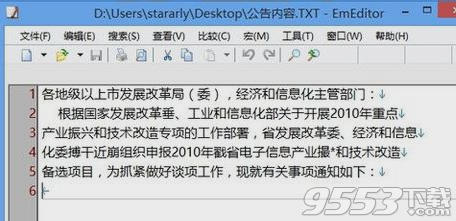
识别出来的内容如下,根据需要在进行段落等的调整:
1.打开文件:选择“文件”菜单,选择打开图像文件的路径,图像文件便显示在管理区用鼠标可将图像文件拖拽到管理区,也可将打开的图像页复制、粘贴到管理区。
2.删除文件:按键盘上的“Delete”键将文件删除。
3.调整文件:选中一个文件或按住Ctrl可以选择多个文件,把文件拖放到要调整的位置。
4.文件格式:本系统支持TIF、BMP、PDF,彩色灰度图还支持JPG格式。
5.文件语言:本系统支持中文简体、英文、简繁体混排方式、以及中英文混排方式。
6.图像文件重命名:选中文件,点击文件菜单选择可保存成TIF、BMP、JPG文件(说明:本系统不支持批量图像文件的改名)。
7.图像文件保存路径:在 中可以设置获取图像文件的路径、名称、格式。如该路径不存在,系统会提示是否创建该路径;如果要选择已存在的某个路径,可以点击“扫描到”按钮,弹出选择路径对话框,选择需要保存图像的路径。
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
1、识别正确率高,速度快带有PDF文件处理功能的OCR软件
2、有批量处理功能,避免了单页处理的麻烦
3、支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件
4、可识别简体、繁体和英文三种语言;具有简单易用的表格识别功能
5、具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能
6、新增打开与识别PDF文件功能
7、支持文字型PDF的直接转换和图像型PDF的OCR识别
8、可以采用OCR的方式将PDF文件转换为可编辑文档
9、可以采用格式转换的方式直接转换文字型PDF文件为RTF文件或文本文件
10、本软件对个人用户免费,无需注册,无功能限制
打开pdf文件,如何看到屏幕左侧的目录树?
1.多数pdf阅读器左侧有屏幕导航工具栏,有个标签符号或“标签”字样,见图,点击,即可出现“目录树”标签。如果原pdf没有的话,里边是空白。
2。目录树标签是可以由自己来建立的,在pdf某个页面,点击标签里“添加新标签”,输入相应文字,就出现自己建立的目录树了。
3.标签栏是可以设定显示的,找一找(因为不知你什么pdf软件),一般是在“工具-选项”下,可以设定“标签”。
对于公司的行政人员来说,如果可以修改pdf文件,那么将为我们写材料的时候提供极大的帮助,因为我们需要的资料很可能就是以pdf文件格式存在的,所以为了以后工作上的需要我们有必须来掌握一下如何从pdf文档内提取文字信息。
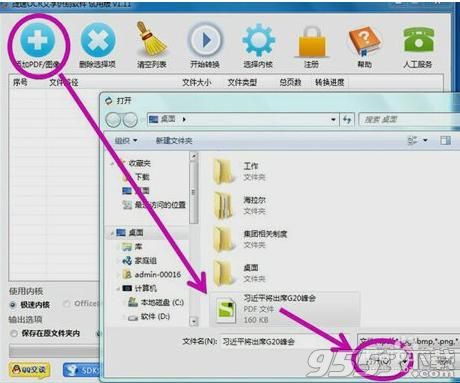
现在就跟着小编的步伐来进行操作吧,首先我们得先从网上下载一个文字识别的软件,然后安装在我们的电脑内,安装好之后打开这个软件。
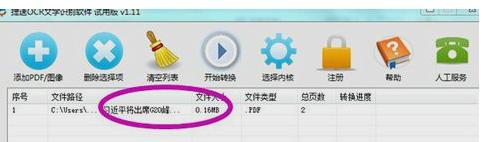
打开软件之后,通过软件上面文件添加的按钮把我们要提取文字的这个Pdf 文档添加到这个软件上,当我们添加成功之后,我们就可以在这个软件上看到我们添加的文件了。
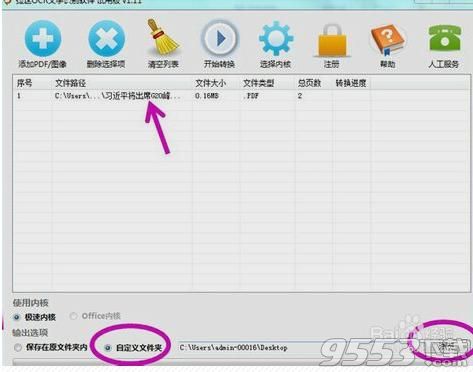
下一步要做的就是来设置文件的保存文件夹,那就是把从pdf内提取的文字要保存的地址,我们可以对这个地址进行修改,你只需要选择软件下方的浏览就可以了,当然了你也可以使用默认的文件夹,默认的就是电脑的桌面;
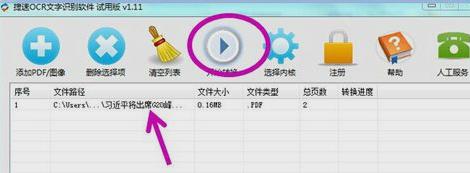
都设置好之后,现在我们要做的就是对文件进行一键式的转换,你只要一键就可以了,软件就会自动来进行文件转换,你只需要点击一下“开始转换”就可以了。
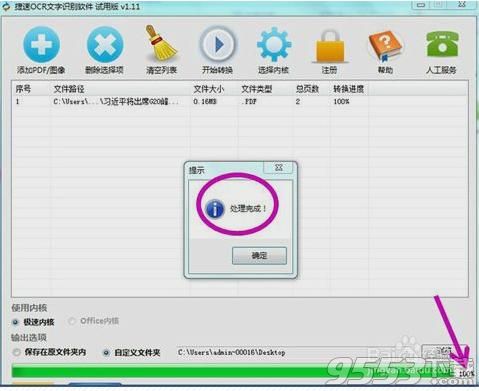
然后你就会看到一个弹出窗口,这里会提示你文字转换完毕,现在你就可以看到一个txt文档了,这里面的内容就是从扫描文件内提取出来的,现在就来对这些内容进行修改吧。
汉王OCR文字识别软件具有识别正确率高,识别速度快的特点。
支持批量处理功能,避免了单页处理的麻烦。
支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;
可识别简体、繁体和英文三种语言;
具有简单易用的表格识别功能;
具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
对部分功能进行了优化
爱aif5颜色取存器 v5.0绿色版
1MB/简体中文/6.7详情
品雅图片分割器 v1.2官方绿色版
29.5KB/简体中文/6.7详情
易当拾色器 v1.2绿色版
257KB/简体中文/6.7详情
ColorPix(颜色拾取工具) v1.2 汉化绿色版 大眼仔~旭作品
426KB/简体中文/5详情
儿童绘画 for Windows 8 官方安装版
8.19MB/简体中文/6.4详情
Jpg Jpeg 图像无损加密器 beta 绿色版
1.06MB/简体中文/6.7详情
电脑图像工具箱 V1.41 绿色版
130.38MB/简体中文/5.7详情
识别看看TryOCR(免费的OCR文字识别软件) v2.0 正式版 官方安装版
14.89MB/简体中文/5.8详情
清华紫光OCR(TH-OCR) V9.0 专业版 简体中文破解版
74.48MB/简体中文/2.7详情
汉王OCR(目前破解最完美的汉王OCR) V6.0 简体中文破解版
46.67MB/简体中文/2.9详情
2寸照片生成器(两寸照片生成器) V1.0 绿色版
146KB/简体中文/1.7详情