- 软件大小:47.58MB
- 软件语言:简体中文
- 软件类型:国产软件
- 软件类别:下载工具
- 更新时间:2023-06-13
- 软件授权:免费版
- 官方网站://www.9553.com
- 运行环境:XP/Win7/Win8/Win10
- 标签:数据采集器 后羿采集器
39.89MB/简体中文/7.5
27.5MB/简体中文/7.5
XPath2Doc(通用网站数据采集及Doc生成工具) v1.0.0.0最新版
14.6MB/简体中文/7.5
29.7MB/简体中文/7.5
34.3MB/简体中文/8
后羿采集器是一款非常好用的数据采集软件,非常适合seo工作者们使用。用户可以通过使用这款软件将所需要的数据从网络上采集下来,非常的方便。需要的朋友欢迎下载使用。
可视化点选,一键采集网页数据
全程拖拽和点击操作,不需要开发更不需要懂技术任何人都能用的网页数据采集器
采集和导出全免费,无限制放心用
全免费的采集软件,导出数据无限制数据可导出到本地文件、发布到网站和数据库等。
可后台运行,速度实时显示
可切换软件后台运行,不打扰您的其他前台工作悬浮窗口实时查看采集速度和采集数据等。
全平台,Win/Mac/Linux都可用
不同于其他采集器,后羿支持所有操作系统版本更新和功能升级同步所有平台。
自定义采集百度搜索结果数据的方法
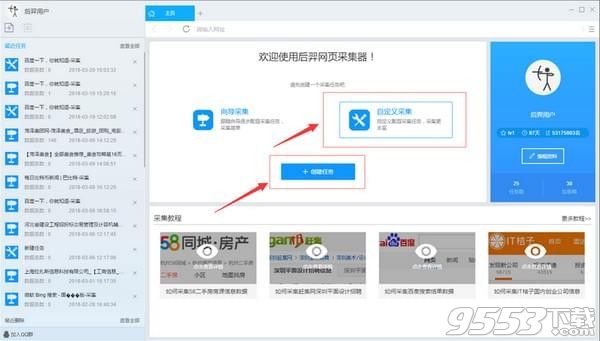
步骤1:创建采集任务
1)启动后羿采集器,进入主界面,选择自定义采集并点击创建任务按钮创建 "自定义采集任务"
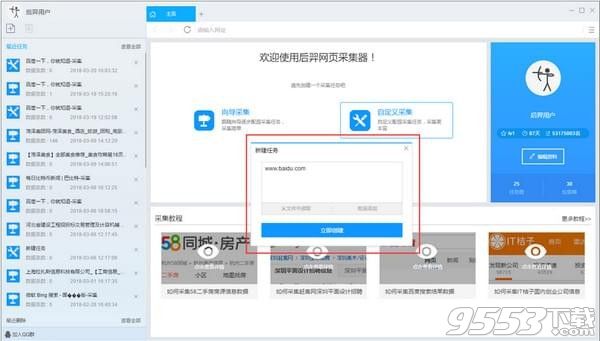
2)输入百度搜索的URL,包括三种方式
1、手动输入:在输入框中直接输入URL,多个URL时须要换行分割
2、点击从文件中读取方式:用户选择一个存放URL的文件,文件中可以有多个URL地址,地址须要换行分割。
3、批量添加方式:通过添加并调整地址参数生成多个有规律的地址
步骤2:自定义采集流程
1)点击创建后自动打开第一个URL进而进入自定义设置页面,默认已经创建了开始、打开网页、结束的流程块。底部模板区用于拖拽到画布中生成新的流程块;点击打开网页中的属性按钮,可修改打开的网址
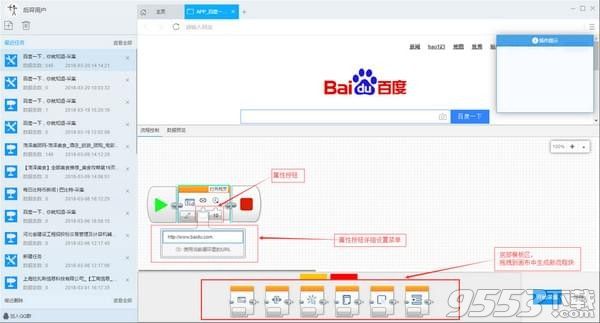
2)添加输入文字流程块:在底部模板区中拖拽输入文字块到打开网页块后面附近,当出现阴影区域的时候可以松开鼠标,此时会自动连接,添加完成
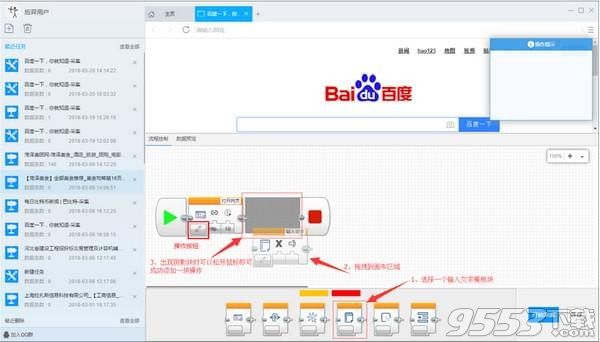
3)生成完整流程图:仿照上面添加输入文字流程块的拖拽流程添加新块:如下图所示:
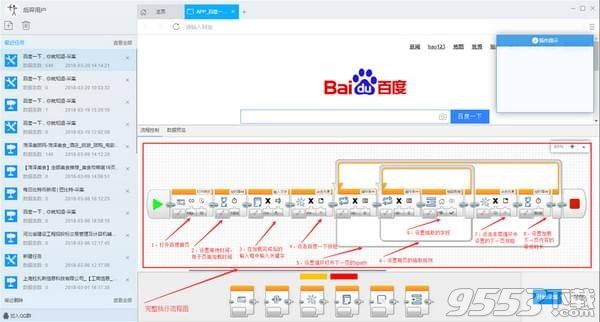
关键步骤块设置介绍
步骤2:定时等待用于等待前面打开网页完成
步骤3:点击输入框Xpath属性按钮,在属性菜单中点击图标进行点选网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
步骤4:用于设置点击开始搜索按钮,点击元素的xpath属性按钮,在菜单中点击点选图标,然后点击网页中的百度一下按钮即可。
步骤5:用于设置循环加载下一列表页。在循环块内部的循环条件块中设置详细条件,此处点击操作按钮,选择单个元素,然后在属性菜单中点击元素的xpath属性按钮,同上进行点选网页中的下一页按钮。循环次数属性按钮可默认为0,即不限制点击下一页的次数。
步骤6:用于设置循环抽取列表页中的数据。在循环块内部的循环条件块中设置详细条件,此处点击操作按钮,选择不固定元素列表,然后在属性菜单中点击元素的xpath属性按钮,然后在网页中连续点选两次抽取第一块和第二块元素。循环次数属性按钮可默认为0,即不限制列表中收取字段的数量。
步骤7:用于执行点击下一页按钮操作,点击元素xpath属性按钮,选择使用当前循环中元素的xpath选项。
步骤8:同理用于设置网页加载等待时间。
步骤9:用于设置在列表页抽取的字段规则,点击属性按钮中使用循环中的元素按钮,选择使用循环中的元素选项。点击元素模板属性按钮在字段表格中点击加减进行添加删除字段,添加字段使用点选操作,即点击加号后鼠标移动到网页元素上点击选择。
4)点击开始采集,启动采集
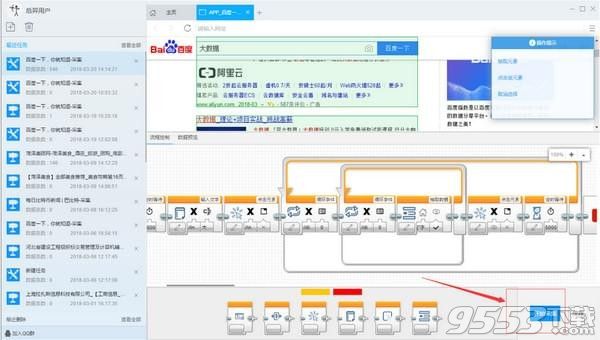
步骤3:数据采集及导出
1)采集任务运行中
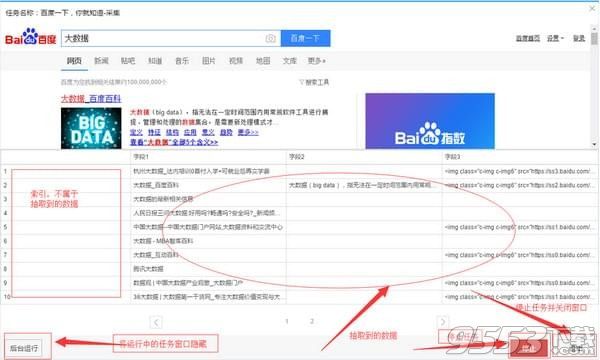
2)采集完成后,选择“导出数据”可以把数据都导出到本地文件
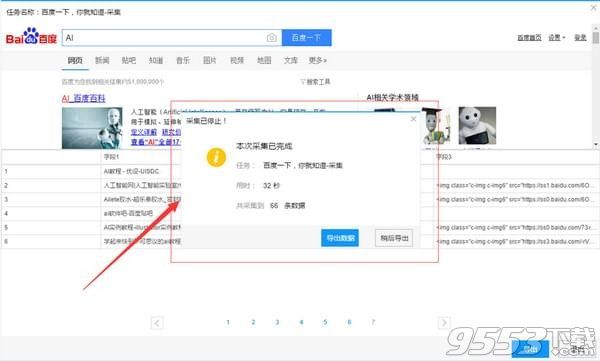
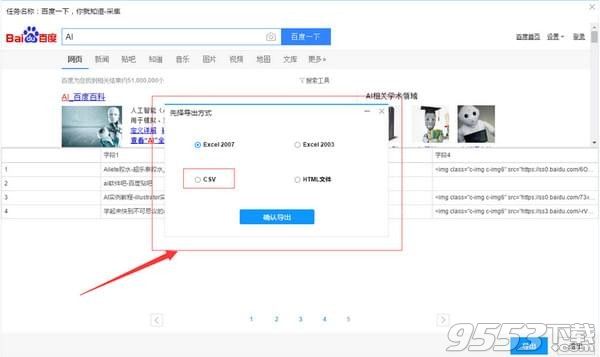
3)选择“导出方式”,将采集好的数据导出,这里可以选择excel作为导出为格式
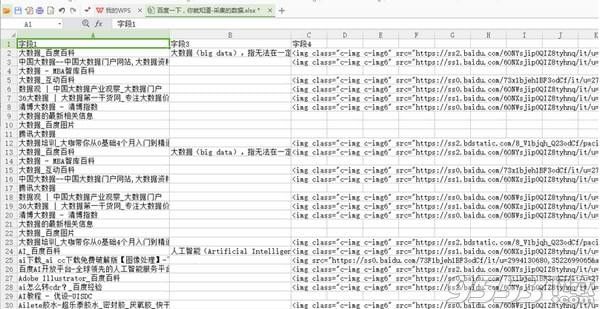
4)采集数据导出后如下图
XX 网站能不能采集?XX 内容能不能采集?
后羿采集器是一款通用网页采集软件,只要是有网址,可以通过网页浏览,您能看得见的内容,大多都是可以采集的(视频比较特殊,得分析具体情况)。
为什么采集数据提前停止了?
如果您遇到的采集提前停止的问题,请按照以下步骤自检一下:
第一步:请确认您在浏览器中能看见多少内容
有的时候搜索显示数量和你最终能看得见的数量不是一致的,请确认您能看见多少条数据,然后再确定采集是提前停止还是正常停止。
第二步:运行日志是否提示“网页数据未显示,等待加载时间不足或被反爬”
在采集过程中,如果遇到这个问题,有以下两种可能性:
第一种可能性是采集速度过快而网页加载时间过慢,从而导致无法采集到网页中的数据。
遇到这种情况时请增加请求等待时间,等待时间长一点之后,就有足够的时间留给网页加载内容。
请求等待时间的设置在 启动设置—>防屏蔽设置中
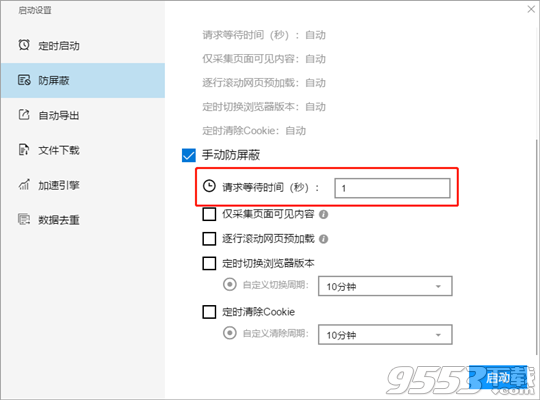
第二种可能性是你遇到了反爬,所谓反爬就是网站针对疑似采集的行为(不同网站对采集行为的定义不一致,例如有些网站觉得你翻页过快就不正常,有些网址觉得你翻页过多就不正常,有些网站觉得你直接输入了详情页的网址就不正常,等等)。
是否遇到了反爬我们可以通过在运行过程中,点击运行界面中的“查看网页”来观察一下当前的网页内容是否正常,是否无法正常显示,是否出现了验证码或者其他非正常内容的提示性文字。
如果出现了上述情况,那么你就是被反爬了。
解决反爬一般有降低采集速度、切换代理IP、手动打码或自动打码等方式,至于哪种方式可以起作用,这个需要测试才知道,不同的网站反爬手段不同,没有一个统一的解决方案。
为什么采集字段不全?
字段不全一般有以下两种情况:
第一种,由于列表元素的结构不同,有些元素中有的字段其他元素中没有,这是正常的现象,请大家先在网页中确认对应元素中是否存在你想要的字段。
第二种,页面结构发生了变化,这种通常会发生在同一个搜索结果中包含多种页面结构的场景,例如百度搜索结果(包含很多种网站),淘宝搜索结果(包含淘宝和天猫)等。
为什么采集数据重复?
首先请确认你已经看过视频教程,你的采集任务没有页面类型的设置问题,即错把单页类型设置为列表类型,或是你错误地理解了循环采集的使用方法。
然后请确定你是多次反复采集数据出现重复还是某一次单独采集出现了重复数据。
在未修改采集任务时,每一次运行采集任务都是从头开始采集,所以每一次采集的数据都是重复的,这是正常的。
如果是在单次采集时出现了重复数据,请确认是否满足以下情况:
第一种:重复数据均为最后一页的数据,这种有可能是翻到最后一页未能停止翻页,请尝试修改采集范围,然后看是否还会出现重复数据的情况。
第二种:重复数据为中间页的数据,这种情况无法直接得出结论。
采集停止了,再运行是不是从头开始?
是的,采集停止之后,下次再直接启动会默认按照上一次的设置从头开始采集。
软件奔溃了,重启后左侧数据都是0,数据丢了吗?
请放心,已经采集到的数据除非你手动删除,否则都不会丢失。
在软件非正常关闭时,重启后左侧任务采集的数据的数量需要手动刷新,你只需点击一下那个数字,就会恢复正常。
IDM(Internet Download Manager) v6.22.1 绿色特别版 zd423作品
7.59MB/简体中文/4.3详情
internet download manager中文破解版下载(Internet Download Manager) v6.29.1免费版
7.59MB/简体中文/8详情
Internet Download Manager注册机(Internet Download Manager) v6.30最新版
7.56MB/简体中文/8详情
迅雷7(Thunder) v7.9.43.5054 官方正式版
32.23MB/简体中文/5.8详情
硕鼠下载器 v0.4.7.11 官方正式版
4.9MB/简体中文/5.8详情
QQ旋风 V4.8 官方安装版
9.97MB/简体中文/3.2详情
迅雷极速版(极速版迅雷) v1.0.31.338 官方最新版
23.2MB/简体中文/7.7详情
MTV下载伴侣 v2.0.3.0 官方安装版
15.2MB/简体中文/7详情
谷歌卫星地图下载器 v2.0 build 659 最新版
19.5MB/简体中文/8.6详情
BitTorrent(bt下载工具) V7.9.2.38398 绿色中文版
7.93MB/多国语言[中文]/6详情
小灰灰淘宝大学视频教程下载神器 v1.0 绿色版
1.13MB/简体中文/1.6详情
迅雷7 v7.9.28.4836 优先体验版
29.82MB/简体中文/2.2详情
